Теги
- Подробности
- июля 15, 2014
- Просмотров: 10149
Из всего живого только человека Создатель наградил даром речи, благодаря чему ему удалось столь значительно развить свои интеллектуальные способности и, по мнению многих философов, стать человеку человеком. Осмелимся предположить, что нечто подобное происходит на наших глазах и с компьютером, интенсивно овладевающим широким спектром речевых технологий от работы со звуковыми файлами до синтеза, распознавания и понимания речи. В этой статье мы коснёмся лишь одного аспекта речевых технологий, а именно, синтеза речи, как наиболее близкого её авторам.
Первые попытки создания в России синтезаторов речи относятся к XVIII веку. Во времена правления Екатерины II Петербургская Академия Наук объявила конкурс на создание говорящей машины. Победителем конкурса стал профессор Петербургского университета Кратценштейн, который построил систему акустических резонаторов, возбуждаемых воздушным потоком и издававших гласные звуки русской речи.
Несколько позже Вольфганг фон Кемпелен разработал более сложную модель генерации связной речи (рис. 1). В ней в роли
резонаторов речевого тракта выступала гибкая трубка из кожи, управляемая оператором. Имелись также отверстия для имитации
носовых полостей и ручки управления свистками, создававшими
фрикативные звуки.
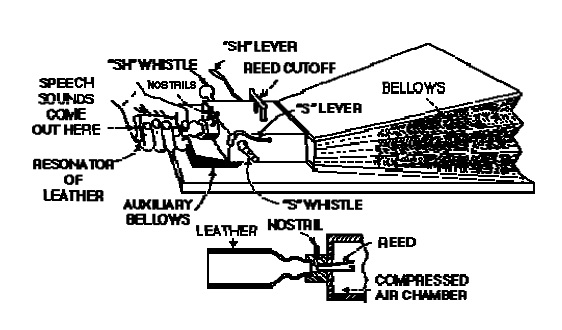
Рис.1. Синтезатор Кемпелена
Следующая заметная попытка синтеза русской речи уже относится к 30-м годам XX века, и была связана с развитием звукового кино и электронной музыки. В московской студии электронной музыки музея Скрябина инженер Е. А. Шолпо решил, что звуковую дорожку можно создать искусственно. Он рисовал в крупном масштабе рассчитанные им звуковые волны, фотографировал их кадр за кадром и проигрывал готовую пленку через кинопроектор. Хотя работа была очень трудоемкой и малопроизводительной, Шолпо озвучил этим способом несколько мультфильмов с вариафона. помощью построенного им прибора - Хорошо знавший работы Шолпо другой сотрудник Студии - Мурзин, выбрал метод синтеза речи с помощью ряда Фурье - в виде суммы элементарных спектральных составляющих, в музыкальной акустике получивших название "чистые тона". Банк "чистых тонов" Мурзин сконструировал в виде стеклянного диска, очень похожего на современный компакт-диск. На его основе был создан синтезатор звуков под названием АНС (от инициалов композитора А.Н. Скрябина, которому посвятил свое изобретение автор). Первые модели говорящих устройств тех времен были очень похожи на музыкальные инструменты, а обучение операторов тоже напоминало обучение музыкантов и требовало немало времени и способностей. История “средних” лет Начало современной историй создания русскоговорящих машин датируется серединой 60-х годов 20 века и непосредственно связано с развитием электроники и вычислительной техники. Немаловажную роль в освоении мирового технологического уровня синтеза речи того времени сыграли научные стажировки в конце 60-х годов М.Ф. Деркача в Лаборатории Фанта (Стокгольм) в Лаборатории Лоренца (Эддинбург), где впервые были разработаны формантные синтезаторы речи (см. рис.2).

Рис. 2. Гуннар Фант с формантным синтезатором
С использованием формантных синтезаторов этих лабораторий были впервые получены образцы синтеза русской речи весьма высокого качества. В последующие годы наиболее интенсивные исследования и разработки синтезаторов речи в СССР проводились в Минске, Ленинграде, Москве, Таллине.
Первая, пока ещё довольно упрощённая модель синтезатора русской речи, разработанная в Минске, «ФОНЕМОФОН-1» (рис. 3)
«заговорила» в начале 70-х гг. и успех в её создании был связан, прежде
всего, с разработкой новых принципов формантного синтеза речевых сигналов.

Позже появилась усовершенствованная модель формантного синтеза речи, в которой были оптимизированы характеристики формантных фильтров «ФОНЕМОФОН-2». В 1979 г. «ФОНЕМОФОН- 3» демонстрировался на Всемирной выставке «Телеком-79» в Женеве (см. рис. 4). Артур Кларк, посетивший павильон СССР, записал в книгу отзывов по поводу синтезатора речи: «Вы предвосхитили мои фантазии «Космической Одисеи – 2001».

Рис.4. Б.М. Лобанов и синтезатор «Фонемофон-3» на Всемирной выставке «Телеком-79» в Женеве
Важную роль в создании серии промышленных синтезаторов речи сыграла разработка цифрового синтезатора «ФОНЕМОФОН-4» (1984).
Его серийный выпуск впервые в СССР был налажен в ПО «Кварц» г. Калининграда благодаря энтузиазму конструктора Валерия Афонасьева. К 1986 г., в сотрудничестве с профессором кафедры фонетики Минского лингвистического университета Еленой
Карневской, была разработана англоязычная версия синтезатора, демонстрировавшаяся на Всемирном конгрессе фонетических наук. Вот факсимиле отзыва об этой демонстрации уже упоминавшегося основоположника формантного синтеза речи Гуннара Фанта (рис. 5).

Рис.5. Отзыв Г. Фанта
Ещё долгое время формантный синтезатор играл ключевую роль в системах синтеза речи по тексту, пока в конце 80-х - начале 90-х годов не был предложен одним из авторов новый микроволновой (МВ) метод синтеза речевых сигналов, воплощённый в синтезаторе
«ФОНЕМОФОН-5» инженером Александром Ивановым. Удивительная компактность созданного синтезатора (всего 64К байт) позволила
оснастить синтезом речи первые персональные компьютеры класса ЕС- 1840 и IBM-XT. До сих пор ещё он используется незрячими (более сотни комплектов программных продуктов для незрячих были созданы и
распространены научным сотрудником Института технической кибернетики Георгием Лосиком в России, Украине и Белоруссии), а его вполне разборчивое звучание можно услышать в комплекте программ на
CD ROM «Говорящая мышь», разработанных группой программистов из МГУ. На основе МВ-метода разработаны версии чешского и польского языков, а также автономный одноплатный модуль синтеза речи, украинско-язычная версия которого некоторое время работала на линиях
киевского метро.
Новейшая история
К середине 90-х годов мощности персональных компьютеров так возросли, что можно было уже подумать не только о компактности программы и разборчивости речи, но и о естественности звучания синтезированного голоса. В этом направлении много сделано было на филфаке МГУ Ниной Зиновьевой и Ольгой Кривновой. В качестве элементарной единицы синтеза они предложили взять не микроволны (отдельные периоды сигнала), а целый звук – аллофон.
Следующий шаг в синтезе русской речи был сделан благодаря сотрудничеству Лаборатории экспериментальной фонетики Санкт- Петербургского университета с Национальным французским центром телекоммуникации (CNET). В течение 2-х лет (1995-96) сотрудники Лаборатории П. Скрелин и др. смогли успешно адаптировать их дифонную технологию применительно к синтезу русской речи. Этот синтезатор стал коммерческим продуктом французской фирмы ELAN под названием DIGALO
В конце 1999 г. в Минске в Институте технической кибернетики
(сейчас – Объединённый институт проблем информатики НАН Беларуси) после почти 5-летнего перерыва вновь возобновились
интенсивные работы по синтезу речи. Сравнительно небольшой коллектив способных молодых программистов сумел на современном уровне программно реализовать многолетний «речевой» опыт. К настоящему времени создана серия «движков», реализующих многоголосый синтез русской речи по тексту, а также синтез белорусской, польской и английской речи. Более того, положено
начало и достигнуты обнадёживающие результаты в разработке принципиально новой технологи – технологии компьютерного
«клонирования» персонального голоса и речи. Но об этом более
подробно будет рассказано ниже.
О чём машине говорить? Зачем Она загoворила?
Говорящий компьютер – это принципиально новое средство человеко-машинного общения, преимущества и возможности использования которого до конца ещё не осознаны широкой общественностью. Здесь уместна аналогия с немым и звуковым кино. Дар речи "великий немой" – кинематограф – получил в конце 20-х годов, но ещё долгое время звуковые фильмы копировали приёмы режиссуры немого кино. Образно говоря, ситуация с современными компьютерами сейчас очень схожая. По-видимому, потребуется ещё немало времени, чтобы синтез речи стал органической частью компьютера и был широко востребован.
Синтезатор речи - это одна из составных частей речевого интерфейса, без которой разговор с компьютером не может состояться. При этом имеется в виду прочтение вслух произвольной текстовой информации, а не проигрывание предварительно записанных звуковых файлов. Синтезатор речи обеспечивает выдачу в речевой форме заранее неизвестной информации непосредственно по орфографическому тексту, генерируемому компьютером.
С точки зрения пользователя, наиболее разумное решение технологии синтеза речи – это включение речевых функций (в перспективе – многоязычных, с возможностями перевода) в состав операционной системы. Точно так же, как мы пользуемся командой PRINT, можно будет применять команду TALK или SPEAK. Такие команды, по-видимому, появятся в ближайшем будущем в меню общеупотребительных компьютерных приложений и в языках
программирования. Важно отметить, что пользователь должен также иметь достаточные возможности по настройке голоса компьютера (индивидуальности звучания, тембра и темпа речи).
Фактически, благодаря синтезатору речи по тексту (имеющему в англоязычной литературе стандартную аббревиатуру TTS – Text-To- Speech), открывается еще один канал передачи данных от компьютера к человеку, аналогичный тому, который мы имеем благодаря монитору или принтеру. Конечно, малоэффективным было бы передавать рисунок голосом, но вот услышать электронную почту или результат поиска в базе данных в ряде случаев было бы весьма удобно, особенно если в это время глаза заняты чем-либо другим. Синтезатор речи совершенно незаменим, если вы хотите получить информацию, находясь далеко от компьютера или в движении. Воспользовавшись обычным или мобильным телефоном, можно будет связаться со своим компьютером и прослушать электронную почту или интересующую вас страничку интернет. В экстренных случаях компьютер сам сможет дозвониться до вас и, выполняя роль секретаря, сообщить необходимую информацию.
Вышеупомянутые функции синтезатора уже сейчас крайне необходимы для лиц, имеющих проблемы со зрением. Инвалидность по зрению имеет особо тяжелые социально-психологические последствия для человека. Как образно заметил д.п.н. Георгий Лосик, «изобретая линзу, ученые не полагали, что она породит такое приспособление, как очки, которое сделает слабовидящих людей неотличимыми от зрячих. Точно так же, изобретая синтезатор речи, они не подозревали, что он совершит подобную революцию в жизни тотально незрячих людей, делая их равными со всеми в мире компьютерной информации».
Вообще, даже простое перечисление ситуаций, в которых будет полезен синтез речи - это материал для большого самостоятельного обзора.
Компьютерное "клонирование" персонального голоса и речи
Многолетние исследования, выполненные в ХХ веке, позволили создать синтезаторы, обеспечивающие качество и разборчивость речи, вполне пригодное для широкого спектра практических приложений. Однако, несмотря на все усилия, синтезированная речь оставалась ещё далёкой по качеству от естественной и обладала узнаваемым машинным акцентом. Причиной этому были не столько уровень наших знаний о процессах речеобразования и о фонетике, сколько нехватка вычислительных ресурсов компьютеров того времени. Сейчас мы можем не ограничивать себя ни объёмом оперативной и дисковой памяти, ни требуемым объёмом вычислений и приступить к созданию системы
синтеза речи по тексту с максимально возможным приближением по звучанию к голосу и манере чтения конкретного диктора.
Такая постановка задачи, хотя и отдалённо, напоминает широко известную биологическую проблему клонирования, когда делается попытка воспроизвести живую копию на основе генетического
материала только одного родителя. В нашем случае, в отличие от классической задачи клонирования, ставится цель создания близкой копии, но не биологической, а компьютерной, и не всего существа в целом (в данном случае человека), а только одной из его интеллектуальных функций: чтение произвольного орфографического текста. При этом ставится задача максимально полного сохранения персональных акустических особенностей голоса, фонетических
особенностей произношения и акцента, а также просодической индивидуальности речи (мелодика, ритмика, динамика). В принципе, в генетике рассматривается и такая возможность, как создание
своеобразных "химер" из разнородного генетического материала. Применительно к технологии клонирования голоса и речи - это тот случай, когда в основу синтеза закладываются, например, акустика
голоса одного диктора, фонетические особенности произношения - другого, а просодическая индивидуальность речи - третьего.
Клонирование акустических характеристик голоса
Персональные акустические характеристики голоса диктора обусловлены множеством факторов, таких как анатомические особенности строения и функционирования элементов речевого аппарата (гортань, голосовые связки, глотка, полость рта и др.), динамические особенности взаимодействия колебаний голосовых связок и резонаторов речевого аппарата (“coupling effect”), а также многое другое. Как известно, попытки имитации персональных характеристик голоса в системах «текст – речь» на основе моделирования физиологических и акустических процессов речеобразования из-за их чрезвычайной сложности до сих пор не привели к ощутимым результатам. В связи с этим наиболее разумным представляется использование отрезков натуральной речевой волны в качестве минимального "генетического материала " для клонирования голоса. В качестве таких отрезков целесообразно выбрать позиционно- комбинаторные варианты фонем – аллофоны или мультиаллофоны, ограниченный набор которых способен обеспечить порождение устной речи произвольного содержания. При этом звуковая волна содержит в себе все персональные особенности голосообразования, проявляющиеся в каждом конкретном аллофоне или мультиаллофоне.
Клонирование фонетических особенностей произношения
В отличие от персональных акустических характеристик голоса, обусловленных, в основном, статическими параметрами речевого аппарата, фонетические особенности произношения обусловлены главным образом динамикой артикуляторных движений, осуществляемых в процессе речеобразования. Присущие данному индивиду скорость артикуляторных движений, характерные запаздывание или опережение движений отдельных артикуляторов, индивидуальные особенности артикуляции того или иного звука (например /Р/), региональный или иностранный акцент, дефекты произношения некоторых звуков обуславливают возникновение своеобразных позиционных и комбинаторных оттенков фонем и создают уникальный набор аллофонов. Таким образом, успех клонирования персональных фонетических особенностей произношения зависит главным образом от успеха имитации персональных особенностей фонемно-аллофонного преобразования.
Клонирование просодических характеристик речи
Комплекс просодических (интонационных) характеристик, включающий мелодику, ритмику и энергетику речи, задаётся закономерными изменениями во времени частоты основного тона – F0, длительности звуков – T и амплитуды звуковых сигналов – A. Характер этих изменений определяется не только конкретным текстом, но и персональной манерой его чтения. Решение задачи клонирования просодических характеристик речи конкретного диктора заключается в создании достаточно полного набора персональных «портретов просодем» его речи.
Технология клонирования
Для успешного клонирования персональных характеристик голоса и дикции необходимо создать достаточно полные наборы звуковых волн аллофонов и интонационных «портретов» речи. В случае, если клонируемый диктор физически доступен, для этой цели используется специально разработанный компактный звуковой массив слов и отрывков текста, начитываемый им в студии или в обычных условиях. Если же клонируемый диктор недоступен, то используются уже имеющиеся записи его голоса на радио, телевидении и др.
Первые результаты по клонированию были получены в лаборатории распознавания и синтеза речи ОИПИ в 2000 году. К настоящему времени набор клонов состоит уже из нескольких мужских и женских голосов, созданных на основе технологии компьютерного клонирования, разработанной авторами и достаточно детально описанной в данной статье. Проведенные опыты по клонированию различных голосов показали, что с использованием специально подобранных массивов слов и отрывков текста достаточно хорошие результаты могут быть получены при длительности звуковой записи порядка 5 – 10 минут. В случае использования произвольных текстов минимально необходимая длительность звуковой записи составляет порядка 20 – 40 минут.
Перспективы компьютерного клонирования
Проводимая нами аналогия между биологической проблемой клонирования и лингво-акустической проблемой синтеза персонализированной речи по тексту может стать не только лишь красивой метафорой. Во-первых, она подчёркивает общенаучную значимость, современность и сложность поставленной задачи. Во- вторых, она выделяет эту задачу в отдельный самостоятельный класс в ряду других задач современных речевых технологий. И, наконец, в- третьих, она стимулирует создание новых специализированных методик, а также автоматических и полуавтоматических методов клонирования персонального голоса и речи в системах "Текст-Речь".
Отметим также некоторые возможные коммерческие аспекты компьютерного клонирования персонального голоса и речи. По нашему мнению, найдётся большое количество пользователей компьютера, желающих, чтобы их персональный компьютер заговорил его собственным голосом. И хотя это всего лишь компьютерный, а не биологический клон, однако обладатели такого "клона" всё же могут быть уверены, что хотя бы частица их сущности – их голос и манера чтения – останутся нетленными. Многим, наверное, было бы интересно, чтобы компьютер говорил голосом близкого ему человека или голосом любимого актёра. Интересным может быть также проект оживления давно ушедших от нас голосов великих людей по оставшимся от них грамофонным или студийным записям. Таким путём можно было бы услышать голос Есенина, читающего не читанные им ранее стихи, или голос знаменитого диктора Левитана, объявляющего новые указы Президента. В более практическом плане разработка эффективной технологии клонирования голоса и речи может значительно повысить привлекательность использования синтезаторов речи в разнообразных компьютерных системах управления благодаря высокому качеству и естественности речи, её персонализации и узнаваемости голоса.
Наряду с указанными положительными примерами применения технологии «клонирования» характеристик голоса и речи человека следует отметить также и определённую опасность её недобросовестного или криминального использования. Можно представить себе, например, провокационные телефонные звонки компьютера, имитирующие голос знакомого человека, или же несанкционированное использование голоса известного актёра или общественного деятеля для целей озвучивания не вполне этичных рекламных роликов. Преступник может представиться по телефону, например, менеджером банка и вынудить вас разгласить данные персонального счета, или с определённой целью завести разговор от имени известного политического лица. Однако это уже выходит за рамки проблем клонирования речи и относится к самостоятельной области информационной безопасности, обладающей собственными мощными средствами противодействия.
В биологии есть понятие о двух основных классах экспериментов по клонированию – in Vitro” (т.е. в пробирке) и – “in Vivo” (т.е. в
живом). Таким образом, можно сказать, что сегодня путём компьютерного воссоздания голоса человека закладываются основы
нового класса экспериментов по клонированию – “in Silico” (т.е. в микросхемах). Это может стать увлекательной перспективой для многих направлений создания систем искусственного интеллекта, наделённых
неповторимыми чертами личности конкретного человека, т.е. не только его голосом, но и определённой суммой знаний, его поведенческими особенностями в той или иной области деятельности.
Предлагаемая читателю монография является обобщением научных результатов, полученных авторами за последние годы. Она посвящена рассмотрению теоретических и экспериментальных основ, а также описанию конкретных практических решений и результатов компьютерного синтеза и клонирования речи.
Введение
Современный уровень развития вычислительной техники и ее повсеместное внедрение в человеко-машинных системах управления делают актуальной организацию общения человека и компьютера в одной из наиболее удобных для человека форм – в форме речевого диалога на естественном языке. Речевой способ общения в человеко- машинных системах имеют принципиальные преимущества, главными из которых являются следующие:
– удобство, естественность и простота общения, не требующая специальной подготовки, что существенно расширяет круг
потенциальных пользователей вычислительных систем и повышает эффективность их использования;
– разгрузка зрительного канала при выводе информации и
устранение ручных манипуляций при вводе, что увеличивает оперативность взаимодействия с компьютером и уменьшает число ошибок оператора;
– возможность использования в качестве терминалов телефонных аппаратов и существующей сети телефонной связи, что позволяет создавать системы массового обслуживания, в том числе с выходом в
Интернет.
Создание систем речевого общения с ЭВМ требует решения двух основных проблем: проблемы автоматического синтеза и проблемы
автоматического анализа и распознавания речи. Наглядным примером роста популярности систем обработки речи является следующий факт: с момента организации в 1989 году крупнейшей конференции по речевым технологиям EUROSPEECH, а затем INTERSPEECH, число ее
участников к 2007 году выросло с 300 до 3000 человек.
В данной статье освещаются вопросы, связанные с решением первой проблемы – проблемы синтеза речи по тексту – и её дальнейшим
развитием – проблемой клонирования в процессе синтеза характеристик голоса и речи конкретной личности.
В полном объеме проблема синтеза речи решается в тех
исследованиях и разработках, в которых ставится задача автоматического синтеза речи неограниченного словарного состава непосредственно по орфографическому тексту сообщения с любыми наперёд заданными характеристиками синтезированного голоса и речи. Эта задача удовлетворительно еще не решена ни для одного из языков, хотя на ее решение были затрачены усилия многих исследователей США, Японии, Франции и других странах. Исследователи сталкиваются здесь с принципиальными трудностями, связанными с созданием интеллектуальной системы, моделирующей речевое чтение человеком произвольных текстов. Следует отметить также, что далеко не все
результаты, полученные для одного языка, годятся при разработке синтезатора речи другого языка. Фонетические системы каждого конкретного языка уникальны. Необходима конкретно-языковая разработка правил ассимиляции, коартикуляции и редукции звуков, просодической (ритмико-мелодической) организации речи.
Исследования, проведенные для создания моделей синтеза речи по тексту, позволили вскрыть тонкие глубинные структуры звуковой организации речевого потока. Удовлетворительный по качеству синтез речи невозможен в принципе, если не созданы всеобъемлющая и детально проработанная акустическая модель полной системы фонем языка, модель их модификаций в речевом потоке под действием комбинаторных, позиционных и просодических факторов. По мере разработки все более качественной модели синтеза речи по тексту накапливается все более достоверная информация об эталонных образцах каждой фонемы и их модификаций в речевом потоке. Эта информация является исключительно ценной для смежной области – автоматического распознавания речи.
Несмотря на широкое развитие исследований в области синтеза речи по тексту, основным критерием качества до недавних пор оставалась степень разборчивости синтезированной речи. Недостаточное внимание, уделяемое естественности синтезированной
речи, ставит барьер для широкого применения систем синтеза речи по тексту в составе интерфейсов компьютерных систем и устройств. Одним из путей повышения естественности синтезированной речи является разработка методов и средств анализа персональных особенностей голоса человека, его дикции и выразительности речи с последующей реализацией этих характеристик при синтезе речи по тексту. При этом решается не только проблема повышения естественности
синтезированной речи, но и проблема воспроизведения произвольного текста с манерой чтения конкретного человека и его голосом.
Такая постановка задачи впервые сформулирована одним из авторов как проблема «компьютерного клонирования». Компьютерное клонирование – это дальнейший этап развития систем искусственного интеллекта, когда моделируется не только сама интеллектуальная функция, но и особенности её проявления у конкрет- ного человека. Введение биологического термина «клонирование» не является самоцелью и возможно в будущем станет таким же продуктивным для компьютерных наук, как «нейронные сети» или «генетические алгоритмы».
В речевых технологиях целью компьютерного клонирования является создание системы синтеза речи по тексту с максимально
возможным приближением по звучанию к голосу и манере чтения конкретного человека. При этом ставится задача максимально полного сохранения персональных акустических особенностей голоса, фонетических особенностей произношения и акцента, а также
просодической индивидуальности речи (мелодика, ритмика, динамика).
Таким образом, исследование проблемы синтеза речи по тексту актуально как в практическом плане создания универсальных систем
речевого вывода информации из компьютера, так и в теоретическом плане создания интеллектуальных персонализированных моделей чтения текстов различных стилей и содержания человеком.
Раздел содержит предисловие, введение, 6 глав и приложения.
В первой главе «Фонетико-акустические основы синтеза речи по тексту» излагаются основные сведения о фонетике русского языка. Рассмотрены артикуляторно-акустические особенности образования звуков речи и принципы просодического оформления речевого потока.
Во второй главе «Методы синтеза фонетико-акустических характеристик речи» рассматриваются методы синтеза речи по тексту и их возможности для передачи персональных характеристик речи, формулируется содержательная постановка задачи компьютерного клонирования персональных характеристик речи.
В третьей главе «Экспериментальные исследования фонетико- акустических и просодических характеристик речи» описаны результаты исследований фонетико-акустических и просодических характеристик речи дикторов, проведенных авторами в ходе реализации задач синтеза и клонирования.
В четвертой главе «Компьютерная модель мультиволнового синтеза речи по тексту» описаны структура системы синтеза речи по тексту и функционирование её основных блоков. Приведены особенности программной реализации и пользовательского интерфейса системы «МультиФон», а также результаты экспериментальных исследований разборчивости синтезированной речи.
В пятой главе «Компьютерное клонирование индивидуальных характеристик речи» формулируются основные этапы технологии компьютерного клонирования персональных характеристик речи, описаны методы реализации технологии компьютерного клонирования. Приведены особенности программной реализации и пользовательского интерфейса систем «ФоноКлонатор» и «ИнтоКлонатор», а также результаты экспериментальных исследований правдоподобия синтезированных с их помощью речевых клонов.
В приложениях приведен богатый фактический материал по описанию используемого текстового корпуса, звуковых, интонационных, лексических, морфологических и синтаксических характеристик устной речи, полезный разработчикам технологий и компьютерных систем и распознавания и синтеза речи, а также исследователям в областях прикладной лингвистики, в частности, фонетики и просодики.
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
