Теги
- Подробности
- июля 18, 2014
- Просмотров: 11790
Основы акустической теории речеобразования достаточно подробно изложены в монографиях Г. Фанта и Д. Фланагана. Схематическое изображение генерации речи человеком приведено на рис. 1.7.
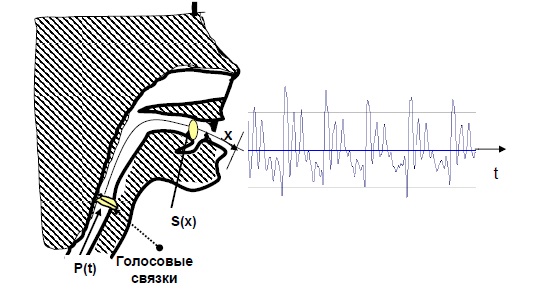
Рис. 1.7. Схематическое изображение генерации речи
Два параллельных канала (ротовой и носовой) образуют единую акустическую систему, возбуждаемую колебаниями голосовых связок, находящихся у основания глотки, либо турбулентным шумом, возникающим в месте сужения ротового канала. Энергия возбуждения создается за счет легочного усилия, затрачиваемого на создание избыточного давления в речевом аппарате. В процессе речеобразования под действием управляющих команд состояние активных артикуляторных органов непрерывно меняется, изменяя конфигурацию всей акустической системы. Как следствие, изменяются её резонансные свойства, т.е. частотная характеристика речевого (голосового) тракта.
Импульсы возбуждения, создаваемые колебаниями голосовых связок, проходя через речевой тракт, трансформируются в речевой сигнал.
Распространение акустических волн в такой системе не удается описать точными математическими методами. Однако при малых потерях и при условии, что длина возбуждаемых волн велика по сравнению с поперечными размерами тракта, а также в случае отсутствия резких изгибов в профиле речевого тракта, распространение акустических волн может быть описано уравнением Вебстера:
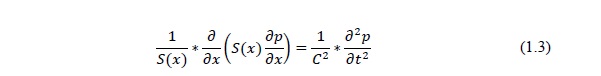
В этом уравнении, имеющем в качестве аргумента x – расстояние до голосовых связок, S(x) является текущей площадью сечения тракта, нормального к направлению распространения волны, p(t) – переменное воздушное давление, создаваемое голосовыми связками, C - скорость распространения звука в воздухе и t – время. Уравнение Вебстера можно проинтегрировать численным методом и рассчитать передаточную функцию речевого тракта. Однако практически непрерывное сечение речевого тракта выгоднее представить последовательностью коротких цилиндрических труб постоянного сечения.
Для однотрубной модели (что подходит для описания нейтрального звука /Э/) максимумы передаточной функции появляются на частотах
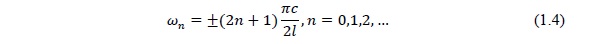
Эти максимумы называются формантами. Если принять l = 17 см (длина голосового тракта взрослого мужчины), то из (1.4) получим, что частоты формант равны: F1 = 500 Гц, F2 = 1500 Гц, F3 = 2500 Гц и т.д. Эти значения формант близки к значениям, полученным экспериментально для реального гласного.
При возбуждении акустической трубы переменным воздушным давлением, создаваемым голосовыми связками, на её выходе появляется
речевой сигнал. На осциллограмме речевого сигнала (рис. 1.8) обнаруживаются два типа колебаний: колебания с частотой основного тона – F0 – и дополнительные формантные колебания c частотами Fi.
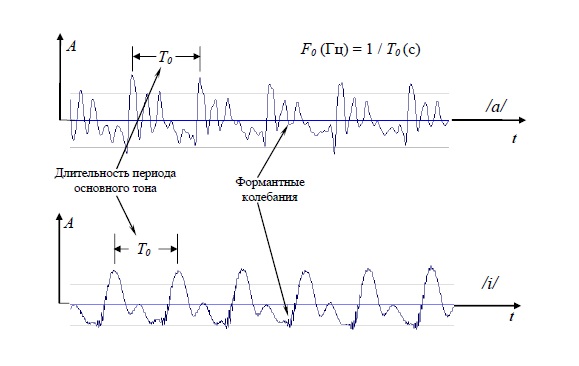
Рис. 1.8. Осциллограмма речевого сигнала для звуков /a/, /i/.
Речевой сигнал s(t) можно представить как свертку возбуждающего сигнала e(t) и импульсной характеристики голосового тракта v(t). Данная модель формирования речевого сигнала во временной области, с примером для звонкого звука, представлена на рисунке 1.9.
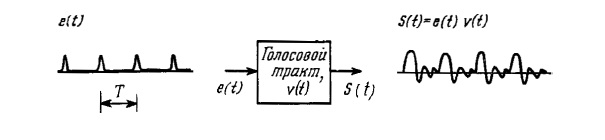
Рис. 1.9. Модель формирования речевого сигнала во временной области
Модель формирования речевого сигнала в частотной области представлена на рисунке 1.10. Спектр речевого сигнала – это произведение спектра Фурье возбуждающей функции (импульсов основного тона) и комплексной частотной характеристики голосового тракта. Последовательности импульсов с периодом T соответствует линейчатый спектр с интервалом между соседними линиями F0 = 1/T.
Частотная характеристика речевого тракта является гладкой функцией частоты, что обусловлено физической структурой голосового тракта, обладающего акустическими резонансами, называемыми формантами.
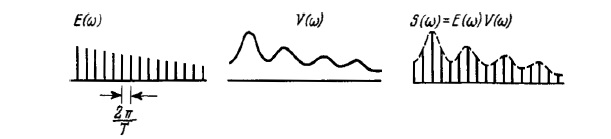
Рис. 1.10. Модель формирования речи в частотной области
Результирующий спектр речевого сигнала является произведением линейчатого спектра возбуждающего сигнала и частотной характеристики голосового тракта, в результате чего спектр речевого сигнала так же является линейчатым, с огибающей, характеризующей передаточную функцию голосового тракта.
На рис. 1.11 представлены двумерные (в координатах «частота – амплитуда») спектрограммы для звуков /a/, /i/. На спектрограммах показаны положения частоты основного тона – F0 – и частоты формант – F1, F2, F3.
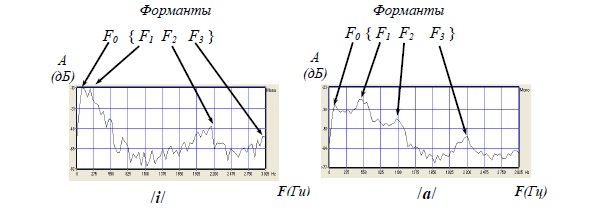
Рис. 1.11. Двумерные спектрограммы для звуков /a/, /i/
Для отображения временной динамики изменения спектральных характеристик используется трёхмерное отображение (т.н. сонограмма), на которой по оси абсцисс отображается время – t, по оси ординат частота – f, а амплитуды спектральных составляющих отображаются степенью почернения. Примеры сонограмм приведены на рис. 1.12. На сонограммах хорошо прослеживаются движения первых 3-х формант.
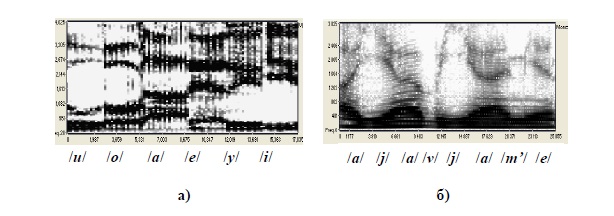
Рис. 1.12. Примеры сонограмм: а) слитно произнесённая последовательность гласных, б) фраза «А я в яме».
Различают широкополосную и узкополосную сонограммы. Широкополосная сонограмма имеет лучшее, чем узкополосная сонограмма, разрешение по времени, что позволяет наблюдать периоды возбуждения в речевом сигнале. В то же время узкополосная сонограмма позволяет наблюдать частотные гармоники возбуждающего сигнала, которые не видны на широкополосной сонограмме. Осциллограмма фразы “Катя уехала”, а так же ее узкополосная и широкополосная сонограммы представлены на рисунке 1.13.
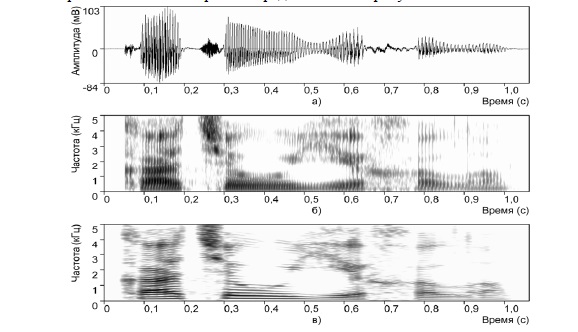
Рис. 1.13. Спектрограммы фразы “Катя уехала”: a) осциллограмма; б) широкополосная спектрограмма; в) узкополосная спектрограмма
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок

Комментарии
Однако, для музыкального звука более важным является не наличие тех или иных формант, а структура и движение формантных колебаний внутри периода
Спасибо за информацию.
RSS лента комментариев этой записи