Теги
- Подробности
- августа 07, 2014
- Просмотров: 3315
Статистическая обработка результатов экспериментальных исследований фонограмм речи проводилась с целью получения некоторых количественных характеристик, полезных с точки зрения персонализации синтагматического членения синтезируемой речи.
К таким характеристикам относятся: сравнительные частоты встречаемости синтагм с различным количеством АЕ, частоты встречаемости пауз различной длительности, частоты встречаемости пар синтагм с различным количеством АЕ. Основные количественные результаты статистической обработки приведены на рисунках 3.23 – 3.25.
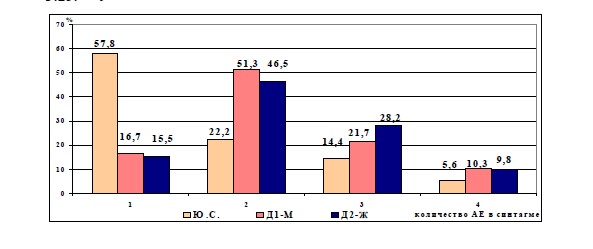
Рис.3.23. Сравнительная частота встречаемости синтагм с различным количеством АЕ
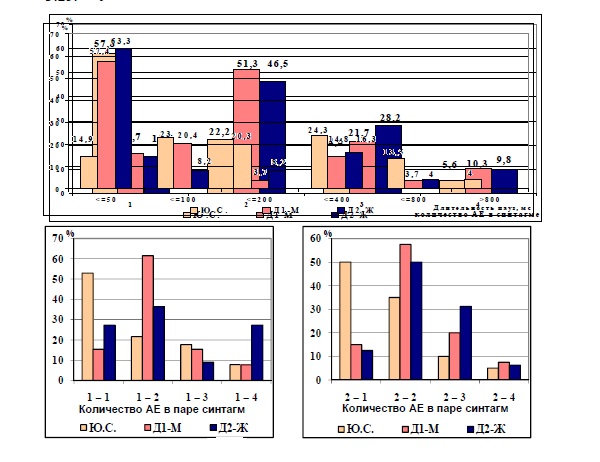
Рис.3.24. Сравнительная частота встречаемости пауз различной длительности
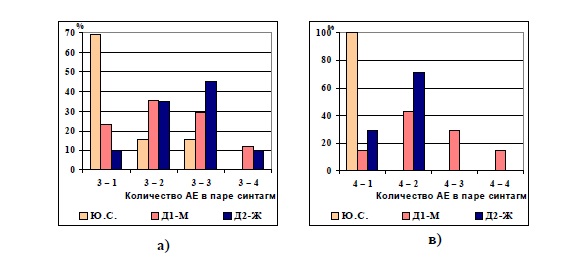
Рис 3.25. Сравнительная частота встречаемости пар синтагм с различным количеством АЕ
Кроме перечисленных выше чисто статистических, внеязыковых характеристик: частот встречаемости синтагм с различным количеством АЕ, пауз различной длительности, пар синтагм с различным количеством АЕ, проведены исследования сравнительной частоты встречаемости пар слов с различными грамматическими категориями на стыке синтагм.
Подсчёт частоты встречаемости пар слов с различными грамматическими категориями на стыке синтагм производился следующим образом. Для каждой пары слов текста, не разделенных знаком препинания, определялась их принадлежность к конкретным частям речи и вычислялось общее количество пар различных частей речи в тексте. Затем вычислялось количество различных пар частей речи, разделенных границей синтагмы. По результатам обработки составлялся двумерный массив частот появления конца синтагмы между различными частями речи. Частота появления конца синтагмы между i- той и j-той частями речи Rij вычислялась по формуле:
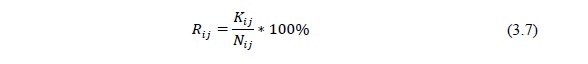
где Nij – общее количество пар частей речи (i – j) в исследуемой фонограмме;
Kij – количество пар частей речи (i – j) в исследуемой фонограмме, разделённых границей синтагмы.
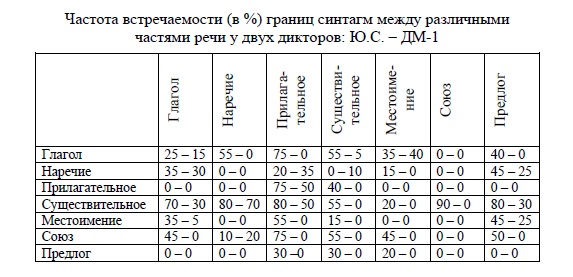
В процессе анализа результатов было принято решение выделять 8 основных частей речи: глагол, существительное, местоимение, наречие, прилагательное, союз, предлог, а все остальные объединить как «другая часть речи».
В табл. 3.4 приведены результаты анализа частоты встречаемости пар различных частей речи на стыке синтагм для 2-х дикторов – Ю.С. и Д-1М. В строках и в столбцах таблицы указаны части речи, на пересечении i-ой строки и j-ого слобца указаны значения Rij (в %) для дикторов Ю.С. и ДМ-1, отделённые символом «–». Значение Rij, равное 0, показывает, что пара частей речи i – j либо вообще не встретилась в анализируемых текстах (в пределах 10-ти процентной статистической достоверности результатов анализа), либо ни разу не была разделена границей синтагмы в речи данного диктора.
Таблица 3.4
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
