Теги
- Подробности
- августа 13, 2014
- Просмотров: 4465
Структура блока предварительной обработки показана на рис. 4.3.
Очистка текста. Очистка текста осуществляется с целью удаления из входного текста графических объектов, ссылок, различных маркеров и других неинформативных для синтеза речи символов. Для реализации этой задачи необходимо иметь БД допустимых символов и объектов, содержащую русские и латинские буквы, знаки пунктуации, цифры, математические символы, а также специальные символы, такие как «@», «^»и т.д. Вообще, в данной БД должны содержаться только те символы, которые могут быть «озвучены» синтезатором речи. Например, если в БД содержатся римские цифры или сложные математические символы, такие как «Σ», «∫», то на последующих этапах обработки текста должны быть блоки, преобразующие последовательности этих символов в слова.
Примечательно, что данный блок с точки зрения разработчика не представляет ни особой трудности, ни особого интереса, и в большинстве случаев при разработке систем синтеза речи реализуется в последнюю очередь. Для пользователей же системы синтеза речи этот блок, напротив, очень важен, поскольку от алгоритмов его работы зависит полнота «озвучивания» входного текста.
Дешифровка чисел. Задача этого блока – преобразовать числа, встретившиеся в тексте, в числительные. При этом необходимо учитывать, что числа, встретившиеся в тексте, могут обозначать целые, десятичные и дробные количественные числительные, порядковые числительные (которые могут быть записаны как арабскими, так и римскими цифрами), дату, время, номера телефонов и т.д. Для корректного преобразования чисел необходимо использовать правила преобразования число – числительное, учитывающие не только число, но и окружающие его слова, сокращения, которые позволяют определить характеристики числа.
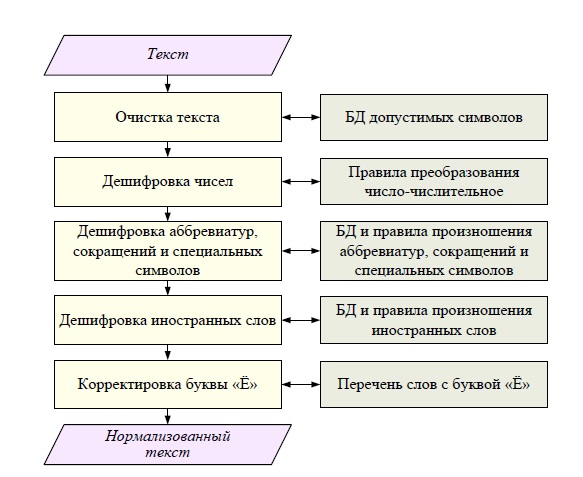
Рис. 4.3. Структура блока предварительной обработки текста
Кроме того, необходимо учитывать, что знаки «.» и «,» могут использоваться как для разделения разрядов в целых числах, так и для отделения целой части от дробной. Например, в записи числа 53,45 запятая отделяет целую часть от дробной, а в записи 378,812,547 служит для разделения разрядов.
Дешифровка аббревиатур, сокращений и специальных символов. При синтезе речи необходимо учитывать, что правила чтения аббревиатур, сокращений и специальных символов отличаются от соответствующих правил для слов русского языка. Для решения этой задачи необходимо преобразовать аббревиатуры, сокращения и специальные символы в слова, для которых применимы стандартные правила, используемые на этапах фонетической и просодической обработки текста. При дешифровке необходимо учитывать следующие факторы:
1. Аббревиатуры в текстах не всегда пишутся заглавными буквами. Это характерно в первую очередь для текстов электронных писем, блогов и других текстов, полученных из различных интернет-ресурсов.
2. Некоторые аббревиатуры и сокращения могут расшифровываться по-разному в зависимости от предметной области, от контекста, например «г.» может означать «город» или «год», «т.» - «товарищ» или «тонн».
3. Некоторые аббревиатуры читаются не в соответствии со стандартными правилами дешифровки, например «США» по правилам расшифровывается как «эс-ше-а», тем не менее общепринятое произношение – «сэ-ше-а».
4. Специальные символы могут преобразовываться по-разному, например «%» – «процент», «процента» или «процентов», «$» - «доллар», «доллара», «долларов».
Для решения этих задач необходимо использовать БД и правила произношения аббревиатур, сокращений и специальных символов. Содержащийся в БД перечень аббревиатур русского языка позволит обнаружить в тексте аббревиатуру даже в случае, если она записана прописными символами. Перечень сокращений и варианты их расшифровки, а также анализ контекста сокращения позволят корректно преобразовать сокращение в слово.
Аббревиатуры произносятся, как правило, по буквам, например «КГБ» – «ка-гэ-бэ», «ФРГ» – «эф-эр-гэ», при этом каждый слог является ударным. Однако наиболее употребительные аббревиатуры, а также аббревиатуры, содержащие большое количество гласных, произносятся, как правило, в одно слово, например, «ЮНЕСКО» – «юнэ́ско». Это должно учитываться правилами произношения аббревиатур и сокращений. Правила произношения специальных символов для корректного преобразования должны учитывать контекст символа.
Дешифровка иностранных слов. В текстах на русском языке могут встречаться интернет-адреса, адреса электронной почты, названия организаций, записанные латинскими символами. Для преобразования таких слов в последовательность русских букв, читаемых по общим правилам, используется блок дешифровки иностранных слов. Этот блок использует БД и правила дешифровки латинских символов. В БД должны содержаться наиболее употребительные иностранные слова, а также их эквиваленты на русском языке, например «Microsoft» – «ма́йкросо́фт», «www» – «три да́блъю». Кроме того, правила дешифровки латинских символов должны содержать русские эквиваленты каждой латинской букве. Тогда в случае, если встретившееся в тексте слово, записанное латинскими буквами, не будет найдено в БД, каждая буква будет преобразована по соответствующим правилам.
Корректировка буквы «ё». Проблема расстановки точек над «ё» - это, пожалуй, проблема только русского языка. Интересно, что человек при чтении текста не задумывается, как правильно прочитать слово, с буквой «ё» или «е», используя для коррекции свои знания о языке. Если же при синтезе вместо, например, слова «ёлка» прозвучит «елка» или вместо «весёлый» – «веселый», такая неточность будет сразу же замечена пользователем. В подавляющем большинстве случаев для корректировки буквы «ё» достаточно лексической информации, а именно БД, содержащей наиболее полный перечень слов с буквой «ё» в русском языке. Тогда в каждом слове текста, содержащем одну или несколько букв «е», каждая из них последовательно заменяется на «ё» и осуществляется поиск соответствующего слова в БД. Однако в некоторых случаях такой информации недостаточно, например, как корректно прочитать слово «все»: «Все в машине?» или же «Всё в машине?». Очевидно, что в этом случае необходимо использовать не только лексический и синтаксический, но и семантический и прагматический анализ. Однако такие ситуации встречаются в текстах довольно редко.
Функционирование блока предварительной обработки текста. Орфографический текст подаётся на вход лингвистического процессора в виде множества символов. На первом шаге поступившее множество необходимо очистить от элементов, не принадлежащих списку допустимых символов. Список допустимых символов состоит из следующих конечных множеств (где все символы указаны в кавычках):
– множество русских заглавных и строчных букв – {«А» «Б», «В», «Г», «Д», «Е», «Ё», «Ж», «З», «И», «Й», «К», «Л», «М», «Н», «О», «П», «Р», «С», «Т», «У», «Ф», «Х», «Ц», «Ч», «Ш», «Щ», «Ъ», «Ы», «Ь», «Э», «Ю», «Я», «а», «б», «в», «г», «д», «е», «ё», «ж», «з», «и», «й», «к», «л», «м», «н», «о», «п», «р», «с», «т», «у», «ф», «х», «ц», «ч», «ш», «щ», «ъ», «ы», «ь», «э», «ю», «я»};
– множество латинских заглавных и строчных букв – {«A», «B», «C», «D», «E», «F», «G», «H», «I», «J», «K», «L», «M», «N», «O», «P», «Q», «R», «S», «T», «U», «V», «W», «X», «Y», «Z», «a», «b», «c», «d», «e», «f», «g», «h», «i», «j», «k», «l», «m», «n», «o», «p», «q», «r», «s», «t», «u», «v», «w», «x», «y», «z»};
– множество цифр – {«1», «2», «3», «4», «5», «6», «7», «8», «9», «0»};
– множество математических знаков – {«–», «+», «/», «*», «=», «<», «>», «%»};
– множество знаков пунктуации – {«.», «,», «:», «;», «(», «)», «!», «?», «-};
– множество специальных знаков – {«~», «`», «№», «#», «@», «$», «^», «&», «|», «\», «{», «}», «[», «]», «"», «'»}.
Блок предварительной обработки осуществляет преобразование в текст следующих последовательностей символов:
– многоразрядные и дробные числа;
– даты из римских цифр;
– обозначения времени и даты;
– телефонные номера;
– знаки пунктуации;
– математические выражения;
– слова с буквой «е» вместо «ё»;
– аббревиатуры;
– сокращения;
– интернет-адреса;
– иностранные слова.
Правила преобразования цифровых символов можно разделить на несколько типов: преобразование количественных и порядковых числительных, десятичных и дробных целых чисел, а также преобразование времени, даты, телефонных номеров.
Опознать порядковое числительное в тексте можно по знаку дефиса, стоящему после цифры, и характерному родовому окончанию. Например, 1-й класс, 2-го класса, 3-му классу и т.д. Для расшифровки порядковых числительных создаётся специальный набор базовых числительных и список родовых окончаний.
Информационный маркер времени в тексте можно определить по следующим признакам:
– [число] – массив целых десятичных чисел.
– [ключевое слово] – группа: час, часы, часов; час.; ч.;
– [ключевое слово] – группа: минут, минута, минуты; м.; мин.
Алгоритм начинает работать, если текущее слово принадлежит массиву целых чисел, а следующее слово принадлежит группе ключевых слов.
Информационный маркер даты можно определить по следующим признакам:
– массив целых десятичных чисел;
– массив римских чисел в диапазоне I – XXX;
– группа слова [ключевое слово]:
– названия месяцев (январь, февраль, март и т.д.);
– год (г.);
– век (в.);
– наша эра, до нашей эры (н.э., д.н.э.);
– столетие (столетия) (ст.).
Если число опознано, но оно не принадлежит ни одному из перечисленных выше классов, система автоматически преобразует его как количественное числительное. Расшифровка количественных числительных происходит с помощью набора базовых числительных: [0, 1, … , 9], [10, 11, … , 19], [20, 30, …, 90], [100, 200, …, 900], [1000, 1000000, 1000000000, ...].
В массовых пользовательских системах синтеза речи функция озвучивания знаков пунктуации является излишней. Однако для людей со слабым зрением такая возможность оказывается достаточно полезной. При включении такой опции система будет автоматически конвертировать все знаки препинания в произносительный вариант, который также задан в лингвистической базе.
Интернет-ресурсы опознаются по списку маркеров, к которым относятся ключевые слова: www, ftp, url, @, http. Каждому такому маркеру ставится в соответствие вариант русского произношения, например, www – даблъю – даблъю - даблъю, ftp – эф - ти - пи и т.д. После информационного маркера следует, как правило, английские буквы, отражающие положение Интернет-ресурса (исключение составляет @, когда маркер стоит в середине). Английские буквы в данном случае читаются раздельно, т.е. каждой английской букве сопоставлено русское произношение, например www.vox.com = даблъю-даблъю-даблъю, точка, ви-оу-экс, точка, ком.
Одной из ключевых проблем при автоматическом синтезе речи является опознание и озвучивание аббревиатур. Существующие в современном русском языке аббревиатуры можно классифицировать по следующим основным группам: 1) буквенные; 2) звуковые; 3) буквенно-звуковые; 4) аббревиатуры смешанного типа. Структурная схема расшифровки аббревиатур и сокращений приведена на рис. 4.4 a. База, составленная из интернет-источников, содержит порядка 1000 аббревиатур и 500 сокращений.
Все слова, состоящие из латинских букв, система идентифицирует как иностранные, расшифровка которых происходит по следующей схеме. Если иностранное слово присутствует в лингвистической базе, то вместо него ставится русский произносительный вариант. Как правило, в такой список входит часто используемые иностранные слова (например, наименование компаний, информационно-компьютерных терминов и др.). В случае, если слово отсутствует в базе, оно расшифровывает побуквенно. Каждой латинской букве ставится соответствующее ей русское произношение.
В электронном варианте русского текста достаточно часто встречается ситуация, когда вместо буквы Ё стоит буква Е. По правилам русской орфографии и пунктуации буква Ё обязательно пишется только в следующих случаях:
– когда необходимо предупредить неверное чтение и понимание слова, например: узнаём в отличие от узнаем, совершённый (причастие) в отличие от совершенный (прилагательное) и т. д.
– когда надо указать произношение малоизвестного слова, например: река Олёкма.
– в специальных текстах: букварях, учебниках русского языка для иностранцев, учебниках орфоэпии и т. п., а также в словарях для указания места ударения и правильного произношения.
В остальных случаях написание буквы Ё необязательно.
Проблема буквы Ё решается следующим образом. Создаётся специальный словарь – «словарь Ё», содержащий по возможности все слова с буквой Ё (количество таких слов в словаре порядка 7000). Обращение к этому словарю происходит в случаях, когда в основном словаре под ударением находится буква Е, а затем проверяется, содержится ли это слово в “словаре Ё”. Если слово содержится в словаре, замена происходит автоматически, в противном случае буква Е остаётся без изменения. Схема алгоритма замены буквы "Е" на "Ё" изображена на рис. 4.4 б.
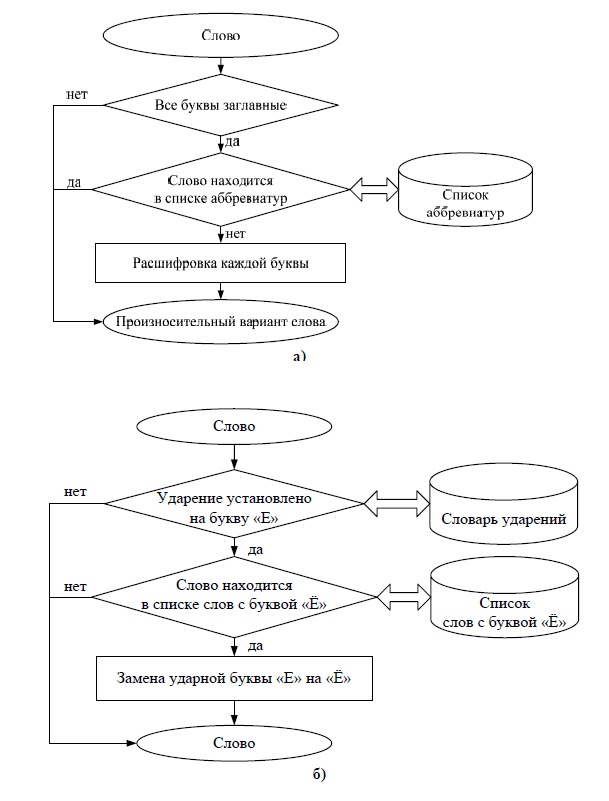
Рис. 4.4. Структурные схемы расшифровки аббревиатур (а), определения буквы «ё» (б)
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
