Теги
- Подробности
- августа 16, 2014
- Просмотров: 4231
Функциональная схема, входные и выходные данные, взаимодействие блоков системы синтеза речи представлены на рис 4.35. В системе реализованы описанные выше алгоритмы обработки текста и речевого сигнала.
Входные данные системы:
– орфографический текст, содержащийся в текстовом файле либо вводимый с клавиатуры.
Выходные данные системы:
– синтезированный речевой сигнал, подаваемый на устройство вывода звука либо сохраняемый в файл в формате WAVE PCM.
На первом этапе синтеза осуществляется очистка и морфо-синтаксическая обработка текста. При этом из текста удаляются символы, не входящие в множество допустимых для синтеза русской речи, осуществляется расшифровка аббревиатур и сокращений, расстановка словесных ударений и указание морфологической категории (МК) для каждого слова текста. Для выполнения первого этапа обработки текста используются орфографический словарь, а также списки аббревиатур и сокращений.
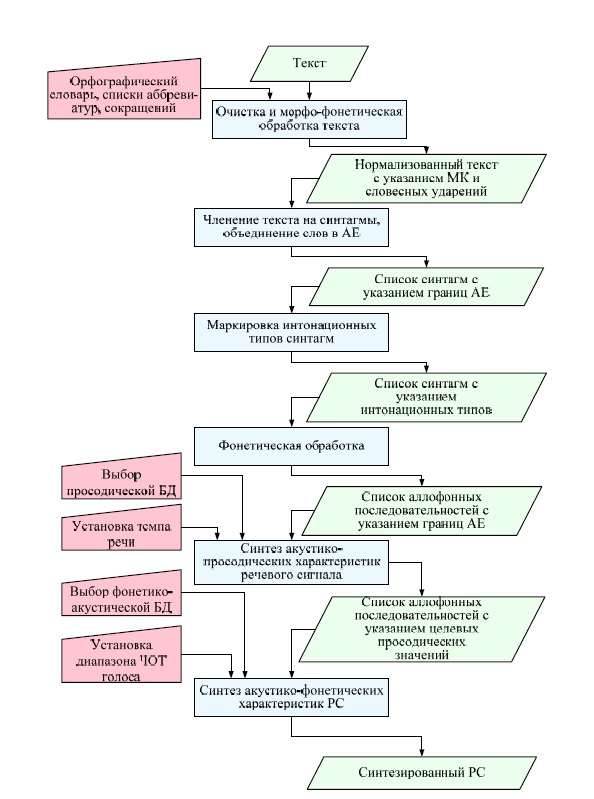
Рис. 4.35. Общая функциональная схема системы синтеза речи по тексту
Нормализованный текст с указанием морфологических категорий и словесных ударений поступает в блок членения на синтагмы и объединения слов в АЕ. В этом блоке на основании указанных МК осуществляется присоединение энклитиков и проклитиков к знаменательным частям речи, определение границ фонетических слов и АЕ, разбиение текста на синтагмы.
Следующий блок синтезатора речи осуществляет маркировку интонационных типов синтагм. Результат работы данного блока – список синтагм с указанием границ фонетических слов и АЕ, а также интонационног типа каждой синтагмы – подвергается фонетической обработке.
В процессе фонетической обработки, реализующей замену слов – фонетических исключений на эквиваленты, преобразования «буква-фонема» и фонема-аллофон, формируется список аллофонных последовательностей, в каждой из которых сохраняются пометы границ АЕ, полученные на предыдущих этапах обработки.
В следующем блоке – блоке синтеза акустико-просодических характеристик – на основании данных просодической БД осуществляется вычисление целевых значений просодических параметров (ЧОТ, амплитуды, длительности) каждого аллофона каждой синтагмы входного списка. На этом этапе обработки пользователь может выбрать просодическую БД, а также указать требуемый темп синтезируемой речи.
Синтез акустико-фонетических характеристик речевого сигнала осуществляется путём выбора из фонетико-акустической БД требуемых аллофонов или мультифонов, их конкатенации и модификации сигнала в соответствии с целевыми значениями просодических параметров. На этом этапе пользователь может выбрать фонетико-акустическую БД, а также указать диапазон изменения ЧОТ для выбранной БД.
Алгоритмы работы системы “Мультифон” соответствую основным положениям, рассмотренным в разделах 4.1 – 4.5.
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
