Теги
- Подробности
- августа 18, 2014
- Просмотров: 2825
Количество экземпляров одного и того же фонетического сегмента, прошедших операцию «отсекающий отбор», зависит от исходного количества таких экземпляров в корпусе, от качества их произношения диктором и от точности аллофонной разметки.
В результате «отсекающего отбора» некоторые экземпляры сегментов могут быть исключены из дальнейшей обработки. Для оставшихся экземпляров выполняется операция «селекция», в результате которой выбирается один, наилучший представитель каждого сегмента.
Фонетико-акустические характеристики каждого экземпляра сегмента, прошедшего операцию «отсекающий отбор», должны быть приемлемыми для помещения данного экземпляра в создаваемую БД элементов компиляции. Учитывая, что созданные элементы будут подвергаться просодической модификации в процессе синтеза речи, целесообразно выбрать экземпляр, наиболее типичный по значениям просодических характеристик: частоты основного тона F0, амплитуды A и длительности T. В качестве такого экземпляра в процессе операции «селекция» выбирается сегмент, имеющий просодические характеристики, наиболее близкие к медианным.
Пусть n – количество аллофонов в сегменте, m – количество экземпляров сегмента. Тогда для ∀ i, 1 ≤ i ≤ n, ∀ j, 1 ≤ j ≤ m, вычисляются значения длительности T i j, средние значения амплитуды Aave i j и средние значения частоты основного тона F0 ave i j i-го аллофона j- го экземпляра сегмента. Для невокализованных аллофонов значение F0 ave i j принимается равным 0. Формируется вектор медианных значений длительностей T i M, амплитуд Aave i M, частот основного тона F0 ave i M аллофонов сегмента. Размерность вектора равна 3*n. Нормированное в диапазоне 0 – 1 расстояние DM j между вектором значений просодических характеристик j-го экземпляра сегмента и вектором медианных значений вычисляется по метрике l1 [182] в соответствии с формулой:
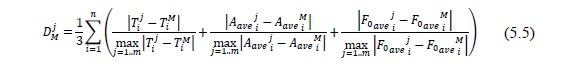
В результате операции «селекция» выбирается экземпляр k сегмента, удовлетворяющий условию:
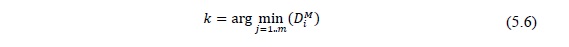
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
