Теги
- Подробности
- февраля 18, 2019
- Просмотров: 4202
Если вы владеете веб-сайтом и заботитесь о его SEO-здоровье, вам следует хорошо ознакомиться с файлом robots.txt на своем домене. Хотите верьте, хотите нет, но огромное количество людей, которые покупают домен, быстро устанавливают CMS WordPress или Joomla и никогда не пытаются ничего сделать со своим файлом robots.txt.
Это опасно. Плохо настроенный файл robots.txt может на самом деле разрушить SEO вашего сайта и снизить шансы на увеличение трафика.
Что такое файл Robots.txt?
Файл Robots.txt назван удачно, поскольку, по сути, это файл, в котором перечислены директивы для веб-роботов (например, роботов поисковых систем) о том, как и что они могут сканировать на вашем веб-сайте. Это веб-стандарт, за которым следуют веб-сайты с 1994 года, и все основные сканеры придерживаются этого стандарта.
Файл хранится в текстовом формате (с расширением .txt) в корневой папке вашего сайта. Фактически, вы можете просмотреть файл robot.txt любого веб-сайта, просто набрав домен, а затем /robots.txt. Если вы наберете это: http://juice-health.ru/robots.txt в адресной строке, вы увидите пример хорошо структурированного файла robot.txt.
Файл простой, но эффективный. Этот файл примера не различает роботов. Команды выдаются всем роботам с использованием директивы User-agent: *. Это означает, что все команды, которые следуют за ним, применяются ко всем роботам, которые посещают сайт для его сканирования.
Указания веб-сканерам
Вы также можете указать конкретные правила для определенных веб-сканеров. Например, вы можете разрешить Googlebot (сканеру Google) сканировать все статьи на вашем сайте, и вы можете запретить веб-сканеру Yandex Bot сканировать определенные статьи на вашем сайте.
Существуют сотни веб-сканеров, которые ищут в Интернете информацию о веб-сайтах, но здесь перечислены 10 наиболее распространенных, которые должны вас беспокоить.
- Googlebot: поисковая система Google
- YandexBot: поисковая система Yandex
- Bingbot: поисковая система Microsoft Bing
- Slurp: поисковая система Yahoo
- DuckDuckBot: поисковая система DuckDuckGo
- Baiduspider: китайская поисковая система Baidu
- Exabot: французская поисковая система Exalead
- Facebot: сканирующий бот Facebook
- ia_archiver: сканер веб-рейтинга Alexa
- MJ12bot: база данных индексации больших ссылок
Если взять приведенный выше пример сценария, если вы хотите, чтобы робот Googlebot проиндексировал все на вашем сайте, но не хотите, чтобы Яндекс проиндексировал рекламный раздел ваших статей, вы добавили бы следующие строки в файл robots.txt.
Как видите, первый раздел только блокирует Google от сканирования вашей страницы входа в WordPress и административных страниц. Второй раздел блокирует Яндекс от того же, но и от всей области вашего сайта, где вы опубликовали рекламные статьи.
Это простой пример того, как вы можете использовать команду Disallow для управления определенными веб-сканерами, которые посещают ваш сайт.
Другие команды Robots.txt
Disallow - не единственная команда, к которой у вас есть доступ в файле robots.txt. Вы также можете использовать любые другие команды, которые будут указывать, как робот может сканировать ваш сайт.
- Disallow: указывает пользовательскому агенту избегать сканирования определенных URL-адресов или целых разделов вашего сайта.
- Allow: позволяет настраивать определенные страницы или подпапки на вашем сайте, даже если вы запретили родительскую папку. Например, вы можете запретить: / about /, но затем разрешить: / about / ryan /.
- Crawl-delay: это заставляет сканер подождать xx количество секунд, прежде чем начинать сканирование контента сайта. Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
- Sitemap: предоставляет поисковым системам (Google, Yandex, Ask, Bing и Yahoo) местоположение ваших карт сайта XML.
Имейте в виду, что боты будут слушать только те команды, которые вы указали при указании имени бота.
Распространенная ошибка, которую допускают люди, - запрещение таких областей, как / wp-admin /, от всех ботов, но затем указание раздела googlebot и запрещение только других областей (таких как / about /).
Поскольку боты следуют только командам, которые вы указали в их разделе, вам необходимо перечислить все те другие команды, которые вы указали для всех ботов (используя User-agent: *).
Имейте в виду, что robots.txt предназначен для того, чтобы законные боты (например, роботы поисковых систем) могли более эффективно сканировать ваш сайт.
Есть много гнусных сканеров, которые просматривают ваш сайт, чтобы делать такие вещи, как сбор адресов электронной почты или кража вашего контента. Если вы хотите попробовать использовать файл robots.txt, чтобы запретить этим сканерам сканировать что-либо на вашем сайте, не беспокойтесь. Создатели этих сканеров обычно игнорируют все, что вы поместили в файл robots.txt.
Зачем вообще что-то запрещать?
Заставить поисковую систему Google сканировать как можно больше качественного контента на вашем веб-сайте - это главная задача большинства владельцев веб-сайтов.
Однако Google расходует только ограниченный бюджет и скорость сканирования на отдельных сайтах. Скорость сканирования - это количество запросов в секунду, которые робот отправляет на ваш сайт во время события сканирования, то есть общее количество запросов, которые робот Googlebot сделает для сканирования вашего сайта за один сеанс. Google «тратит» свой бюджет сканирования, сосредотачиваясь на тех областях вашего сайта, которые очень популярны или изменились в последнее время.
Вы не слепы к этой информации. Если вы посетите "Инструменты Google для веб-мастеров", вы увидите, как сканер обрабатывает ваш сайт.
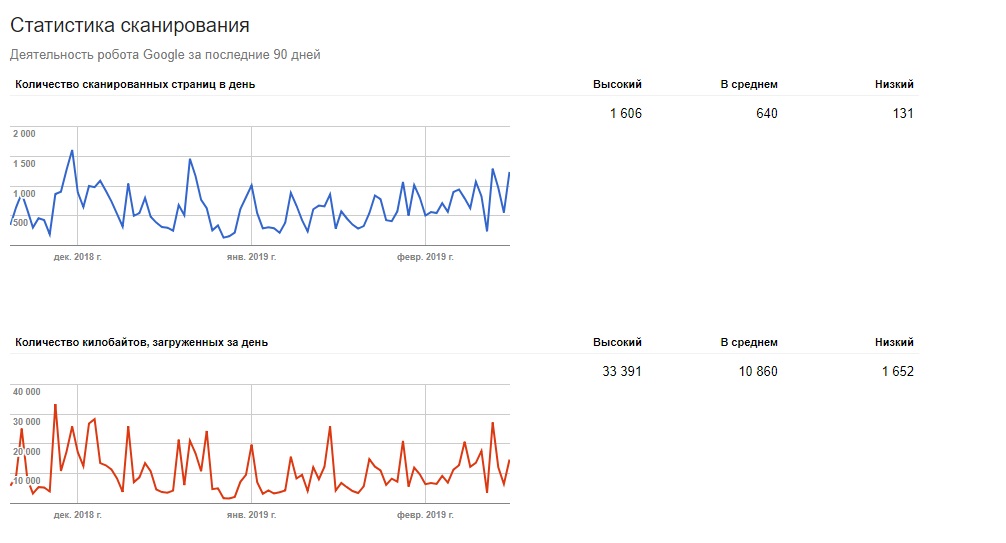
Как вы можете видеть, сканер постоянно поддерживает активность на вашем сайте. Он не сканирует все сайты, а только те, которые он считает наиболее важными.
Зачем заставлять Googlebot решать, что важно на вашем сайте, если вы можете использовать файл robots.txt, чтобы самостоятельно сообщить ему, какие страницы наиболее важны? Это предотвратит трату времени Googlebot на страницы с низким значением на вашем сайте.
Оптимизация сканирования
Инструменты Google или Яндекс для веб-мастеров также позволяют вам проверить, правильно ли Googlebot читает ваш файл robots.txt и есть ли ошибки.
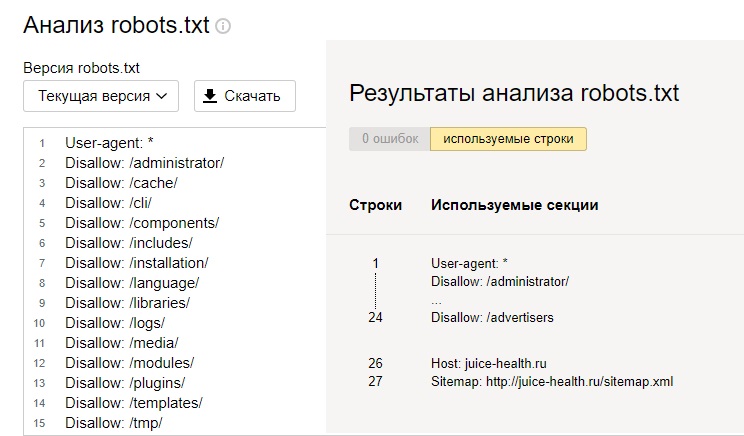
Это поможет вам убедиться, что вы правильно структурировали свой файл robots.txt.
Какие страницы вы должны запретить Googlebot? Это хорошо для SEO вашего сайта, чтобы запретить следующие категории страниц.
- Дублирующиеся страницы (например, страницы для печати)
- Страницы с благодарностью после заказов на основе форм
- Форма заказа или информационного запроса
- Контактные страницы
- Страницы входа
Не игнорируйте свой файл Robots.txt
Самая большая ошибка, которую делают неопытные владельцы веб-сайтов, — это даже не просмотр их файла robots.txt. Худшая ситуация может быть в том, что файл robots.txt фактически блокирует ваш сайт или области вашего сайта от сканирования.
Обязательно просмотрите файл robots.txt и убедитесь, что он оптимизирован. Таким образом, Google и другие важные поисковые системы «видят» все вещи, которые вы предлагаете миру на своем веб-сайте.
Читайте также




Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
