Теги
- Подробности
- августа 18, 2014
- Просмотров: 3255
Функциональная схема, входные и выходные данные, взаимодействие блоков системы представлены на рис 5.6. В системе реализованы описанные выше этапы создания БД элементов компиляции.
Входные данные системы:
– предварительно обработанная фонограмма записи – набор речевых синтагм, каждая из которых хранится в виде оцифрованной звуковой волны в отдельном файле в формате WAVE PCM;
– предварительно обработанная стенограмма записи – текстовый файл, содержащий пометы границ синтагм;
– базовая БД звуковых волн аллофонов. В качестве такой БД используется БД элементов компиляции синтезатора, созданная «вручную» или автоматически на основе записей голоса одного из дикторов.
Выходные данные системы:
- БД аллофонов и мультифонов голоса «клонируемого» диктора.
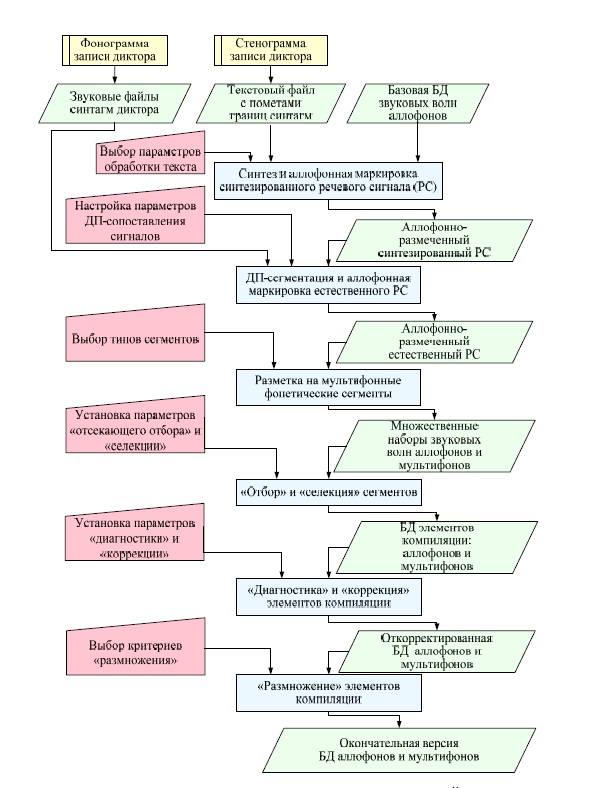
Рис. 5.6. Общая функциональная схема автоматической системы клонирования фонетико-акустических характеристик речи
На первом этапе синтеза осуществляется фонетическая обработка текста, включающая расстановку словесных ударений, преобразования «буква-фонема» и «фонема-аллофон». Результат обработки – последовательность аллофонов – передаётся на второй этап, где происходит выбор звуковых волн аллофонов из БД, их компиляция и аллофонная маркировка.
Настройка параметров обработки текста включает выбор используемого словаря с пометами позиции ударения, а также указание индикаторов границ фонетических слов и синтагм в тексте.
Каждая пара синтагм: «аллофонно-размеченный синтезированный сигнал – естественный сигнал», поступает в блок ДП-сегментации и аллофонной маркировки естественного РС, где осуществляется анализ спектральных признаков сигналов, их ДП-сопоставление и перенос маркеров границ аллофонов с синтезированного на естественный РС. В системе реализована настройка параметров вычисления спектральных признаков и параметров ДП-сопоставления.
Аллофонно-размеченный естественный РС поступает в блок разметки на фонетические сегменты. Пользователь системы может выбрать типы получаемых сегментов, среди которых аллофоны различного типа: ударные гласные, гласные первой степени редукции, гласные второй степени редукции, согласные; диаллофоны типов ГГ, СГ, СС, ГС, а также внутрисловные и внутрисинтагменные аллослоги первого, второго и третьего типов.
Результат работы данного блока – множественные наборы звуковых волн сегментов указанных типов – подвергается операциям «отсекающий отбор» и «селекция». На этом этапе обработки пользователь может указать параметры «отсекающего отбора»: пороги сходства синтезированного и естественного сегментов по временны́м и акустическим характеристикам. В результате операций «отсекающий отбор» и «селекция» создаётся первая версия БД аллофонов и мультифонов, содержащая по одному экземпляру элементов компиляции для каждого фонетического сегмента.
При осуществлении следующего этапа обработки – «диагностики» и «коррекции» – пользователь системы может изменить значения весовых коэффициентов акустических и временны́х характеристик, а также порог сходства периодов основного тона. Откорректированная БД аллофонов и мультифонов поступает в блок «размножения». Настройка параметров на этом этапе включает выбор критериев размножения: типы «размножаемых» мультифонов, характеристики «заменяемых» аллофонов гласных. Результатом работы системы является окончательная версия БД аллофонов и мультифонов.
Промежуточные данные, получаемые в результате работы каждого из блоков, могут быть сохранены для дополнительного анализа и коррекции опытным экспертом-фонетистом.
Все блоки системы работают независимо и могут использовать как данные, полученные в текущем сеансе в результате работы предыдущих блоков, так и предварительно сохранённые промежуточные данные.
Алгоритмы работы основных блоков системы «ФоноКлонатор» соответствуют положениям, рассмотренным в разделах 5.2, 5.3.
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
