Теги
- Подробности
- августа 20, 2014
- Просмотров: 2769
Система «ФоноКлонатор» использовалась для получения компьютерных клонов голосов пяти дикторов: трёх женщин и двух мужчин.
Двое из них: женщина (ДЖ1) и мужчина (ДМ1) – являлись профессиональными дикторами, трое – не профессиональными: две женщины (ДЖ2, ДЖ3) и один мужчина (ДМ2). Фонограммами для создания каждого из клонов являлись записи мини-и макси-тестов, описанных в приложениях В1, В2. Запись фонограмм осуществлена в акустических условиях профессиональной радиостудии. Результатом работы системы явилось создание пяти БД элементов компиляции: БД_Ж1, БД_Ж2, БД_Ж3, БД_М1, БД_М2.
В качестве иллюстрации акустических особенностей реализации основных аллофонов гласных и согласных фонем русской речи в Приложении 4 представлены их спектральные портреты на примере аллофонов, взятых из БД_М1.
Перед применением процедуры автоматического клонирования фонограммы записей и соответствующие стенограммы были обработаны вручную следующим образом:
- из фонограмм и стенограмм были удалены синтагмы, в записи которых присутствовали различного рода шумы (например, шелест страниц);
- содержимое текстов было приведено в соответствие с фонограммами (поскольку некоторые слова были прочитаны дикторами неверно);
- в текстовых файлах стенограмм записей были проставлены ударения, соответствующие ударениям, сделанным дикторами при чтении текста (которые не всегда являлись каноническими, например, «при́няла», «на́чался»);
- в звуковых и текстовых файлах были установлены пометы границ фонетических синтагм, реализованных в речи дикторов.
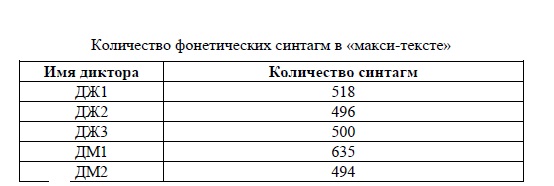
Количество синтагм в «мини-тексте» (см. Приложение 1.1) для всех дикторов было одинаковым и равнялось 69. Количество синтагм в «макси-тексте» (см. Приложение 1.2) для каждого из дикторов приведено в таблице 5.2. Отличия в количестве синтагм для разных дикторов связано с их индивидуальными особенностями прочтения отдельных предложений «макси-текста».
Таблица 5.2
Создание компьютерных голосовых клонов проходило в два этапа. На первом этапе входными данными системы являлись:
– мини-текст с пометами границ синтагм;
– список звуковых файлов синтагм мини-текста;
– имеющиеся БД элементов компиляции женского и мужского голосов. Для обработки естественной речи женских голосов использовалась БД элементов компиляции женского голоса, а для обработки естественной речи мужских голосов – БД элементов компиляции мужского голоса.
При осуществлении операции «отсекающий отбор» использовались: порог сходства временны́х признаков β1 = 0,6 и порог сходства акустических признаков β2 = 0,7. При осуществлении операций «диагностика» и «коррекция» использовались: весовой коэффициент α = 0,4 и порог сходства периодов β = 0,7.
Результатом первого этапа явились вновь созданные БД аллофонов для каждого голоса. Время автоматического создания БД на персональном компьютере, имеющем процессор AMD Athlon 2000 с реальной тактовой частотой 1,67*109 Гц, составило 7 ± 1,5 минуты.
Количество автоматически созданных аллофонов для каждой из БД приведено в таблице 5.3.
Таблица 5.3

Аллофоны, присутствующие в мини-тексте, но не прошедшие операцию «отсекающий отбор», добавлялись в БД «вручную».
На втором этапе – пополнения БД мультифонными сегментами – входными данными системы являлись:
– мини-и макси-тексты с пометами границ синтагм;
– список звуковых файлов синтагм мини-и макси-текстов;
– вновь созданные БД аллофонов для каждого из женских и мужских голосов.
При осуществлении операции «отсекающий отбор» использовались менее жёсткие критерии: порог сходства временны́х признаков β1 = 0,5, порог сходства акустических признаков β2 = 0,6. При осуществлении операций «диагностика» и «коррекция» использовались: весовой коэффициент α = 0,3; порог сходства периодов β = 0,6.
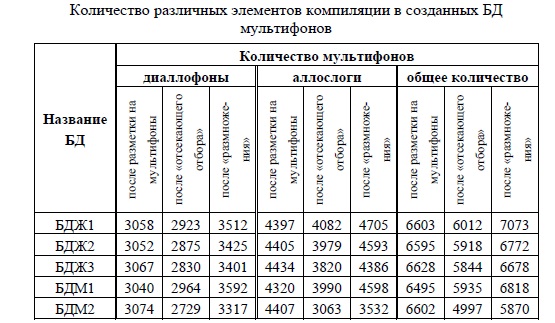
Количество созданных мультифонов для каждого из дикторов приведено в таблице 5.4. Количество диаллофонов и аллослогов до операции «отсекающий отбор», которое определялось по соответствующим текстовым файлам, не является одинаковым для всех дикторов, поскольку, во-первых, количество фонетических синтагм в макси-тексте было разным для различных дикторов, во-вторых, некоторые слова были произнесены дикторами с фонетическими ошибками или с неканоническим ударением. Общее количество мультифонов не является суммой диаллофонов и аллослогов, так как некоторые аллослоги, полученные по алгоритмам, описанным в разделе 5.2, являются диаллофонами.
Таблица 5.4
Время автоматического создания БД мультифонов на персональном компьютере, имеющем процессор AMD Athlon 2000 с реальной тактовой частотой 1,67*109 Гц, составило 42 ± 4 минуты.
Похожие статьи

Последние

Отзывы о компании vps-хостинга Serv-tech

Какие аксессуары нужны для экшн-камеры GoPro

7 тенденций веб-дизайна на 2023 год

Обзор камеры iPhone 14 Pro: маленький шаг, огромный скачок
